다익스트라 알고리즘
- 한 노드에 대해서 다른 모든 노드까지의 최단 거리를 구하는 알고리즘이다.
- 음수 가중치(음의 간선, 음의 값)이 없어야 한다는 특징이 있다.
- 초기 모델은 가장 비용이 싼 정점을 구하기 위해 모든 정점을 탐색하는 구조이기 때문에 시간 복잡도가 O(n^2)이지만
개선된 모델인 우선 순위 큐를 사용하는 모델의 경우 O(MlogN)까지 줄일 수 있다. (M은 간선, N은 정점) - 다익스트라 알고리즘은 기본적으로 그리디 알고리즘과 다이나믹 프로그래밍 기법을 사용한다.
다익스트라 알고리즘의 과정
크게 알고리즘의 동작과정은 다음과 같다.
- 출발지 노드를 기준으로 시작한다. (출발지 노드로 부터 다른 모든 노드까지 최단 거리를 구하는 알고리즘이기 때문)
- 아직 방문하지 않은 정점 중에 출발지에서 가장 짧은 정점을 찾아서 방문한다.
- 해당 정점을 거쳐서 갈 수 있는 총 비용이 현재 최소 비용 배열에 기록되어 있는 배열의 비용보다 작은 값인 경우 값을 갱신하여 준다.
(우선 순위 큐에 담기는 우선순위의 기준은 가지고 있는 비용을 우선 순위로 한다.)
필요한 요구사항들을 한번 정리해보면
- 정점 정보 변수 (N)
- 간선 정보 변수 (M)
- 정점 연결 정보를 저장할 연결 리스트 (graph) -> 리스트로 이루어진 리스트를 활용할 것이다.
- 정점 방문을 체크할 배열 (v)
- 시작 노드로 부터 다른 노드까지의 최소 비용 거리를 저장할 배열 (d)
이 정도로 생각할 수 있다.
필자는 우선순위 큐를 활용해서 구현을 하였다. 또한 노드의 경우 Comparable 인터페이스를 구현하는 방법이 있고 우선 순위 큐에 람다식을 사용해 우선 순위 기준을 넣어주는 방법이 있다. 필자는 우선 순위 큐에서 기준을 정해주는 방법을 사용하였다.
우선 전체적인 과정을 그림으로 한번 보자
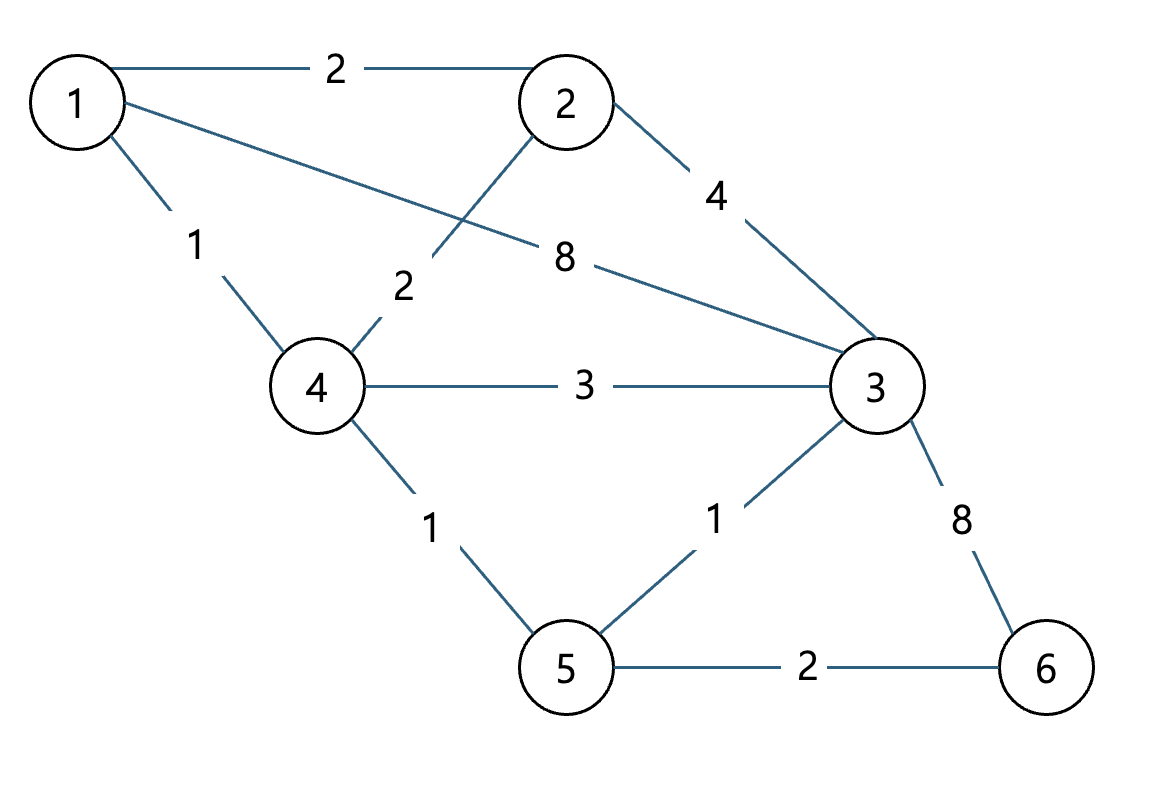
1번 정점에서 시작해서 다른 정점들로 가는 최단 거리를 구하는 과정을 살펴보자.
전체 코드의 일부를 과정에 해당하는 부분의 코드를 넣어두었다.
boolean[] v = new boolean[N + 1]; // 방문 체크 배열
int[] dist = new int[N + 1]; // 거리를 체크할 배열
int INF = 100000001; // 무한대의 비용 설정
Arrays.fill(dist, INF); // 거리 배열을 초기화
d[start] = 0; // 시작 노드의 거리는 0

그 다음 큐에 시작노드와 시작노드의 비용인 0을 넣어준다.
PriorityQueue<Node> pq = new PriorityQueue<>((n1, n2) -> n1.cost - n2.cost);
pq.add(new Node(start, 0));
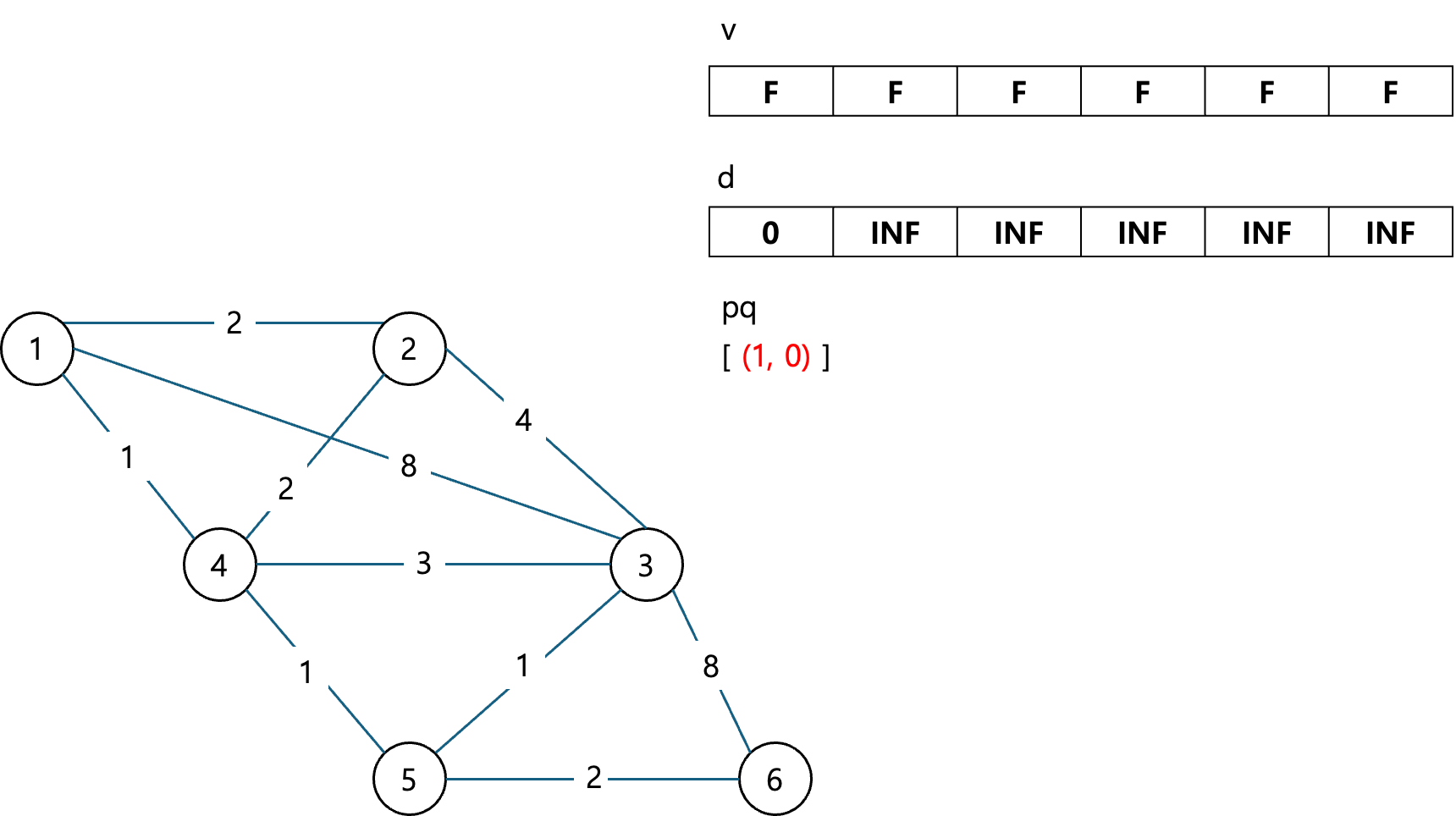
그리고 큐가 비어있지 않은 동안 반복하는 과정이다.
큐에서 제일 비용이 가장 낮은 노드를 하나 꺼낸다. (1, 0)은 방문하지 않았으므로 방문체크를 하고 현재 정점과 연결된 정점들을 확인한다.

1과 연결된 정점들을 탐색하면서 기존 최소 비용이 현재 노드를 거쳐서 가는 비용보다 저렴한지 확인한다.
d[2] > d[1] + (1에서 2로 가는 비용)
- d[2] = INF > d[1] + 2 = 2 이므로 d[2] = 2로 갱신!
- 우선 순위 큐에 정점 2와 갱신된 2의 최소 비용 2를 넣는다.
d[3] > d[1] + (1에서 2로 가는 비용)
- d[3] = INF > d[1] + 8 = 8 이므로 d[3] = 8로 갱신!
- 우선 순위 큐에 정점 3과 갱신된 3의 최소 비용 8을 넣는다.
d[4] > d[1] + (1에서 4로 가는 비용)
- d[4] = INF > d[1] + 1 이므로 d[4] = 1로 갱신!
- 우선 순위 큐에 정점 4와 갱신된 4의 최소 비용 1을 넣는다.
해당 로직의 코드는 다음과 같다.
while (!pq.isEmpty()) {
int nowVertex = pq.poll().index; // 우선순위 큐에서 뽑은 정점
if (v[nowVertex]) { // 정점이 이미 방문한 노드라면 거리 체크 안함
continue;
}
v[nowVertex] = true;
for (Node next : graph.get(nowVertex)) {
if (dist[next.index] > dist[nowVertex] + next.cost) {
dist[next.index] = dist[nowVertex] + next.cost;
pq.add(new Node(next.index, dist[next.index]));
}
}
}위의 코드는 계속 반복될 예정이다.
지금까지의 과정을 그림으로 표현하면 다음과 같이 된다.

그리고 우선 순위 큐가 비어있지 않으므로 우선 순위 큐에서 노드를 꺼내 확인한다.
- 4가 비용이 제일 저렴하므로 큐에서 꺼내진다.
- 4는 방문한 적이 없으므로 방문 처리를 한다.
- 그 다음 4와 연결된 정점들을 확인하면서 비용을 갱신해준다.
- 해당 노드에 현재 갱신된 비용보다 4를 거쳐서 갈 수 있는 비용이 더 저렴하면 그 비용으로 거리 배열을 갱신한다.

4와 연결된 정점의 경우 2, 3, 5가 있다.
d[2] > d[4] + (4에서 2로 가는 비용) -> d[4]가 1에서 4로 가는 비용이므로 1 -> 4 -> 2라고 생각하기
이 경우는 바로 2로 가는 비용이 더 저렴해서 갱신 x
d[3] > d[4] + (4에서 3로 가는 비용)
- 8 > 1 + 3 의 경우 더 저렴하므로 d[3] = 4로 갱신한다.
- 우선 순위 큐에 정점 3과 갱신된 3의 최소 비용 4를 넣는다.
d[5] > d[4] + (4에서 5로 가는 비용)
- INF > 1 + 1 의 경우 더 저렴하므로 d[5] = 2로 갱신한다.
- 우선 순위 큐에 정점 5와 갱신된 5의 최소 비용 2를 넣는다.
지금까지의 결과를 그림으로 보면 다음과 같다.

그 다음 우선 순위에서 노드를 뽑는다.
- 2번 노드의 경우가 가장 비용이 저렴하기 때문에 2번 노드가 nowVertex가 된다.
- 2번 정점 방문하지 않았으므로 방문처리
- 2번과 연결된 정점들을 탐색하면서 거리배열을 갱신해준다.

- d[1]의 경우 갱신하지 않는다. 2번을 거쳐가는 비용이 2
- d[3]의 경우 갱신하지 않는다. 2번을 거쳐가는 비용이 6
- d[4]의 경우 갱신하지 않는다. 2번을 거쳐가는 비용이 4
탐색이 끝났으므로 큐에서 노드를 하나 뽑는다.
노드의 정점은 5이고 nowVertex는 5로 갱신된다.

d[3] > d[5] + (5에서 3으로 가는 비용)
- 4 > 2 + 1 = 3 이므로 d[3] = 3으로 갱신!
- 우선 순위 큐에 정점 3과 갱신된 3의 최소 비용 3을 넣는다.
d[4]는 갱신되지 않는다.
d[6] > d[5] + (5에서 6으로 가는 비용)
- INF > 2 + 2 = 4이므로 d[6] = 4으로 갱신!
- 우선 순위 큐에 정점 6과 갱신된 6의 최소 비용 4를 넣는다.
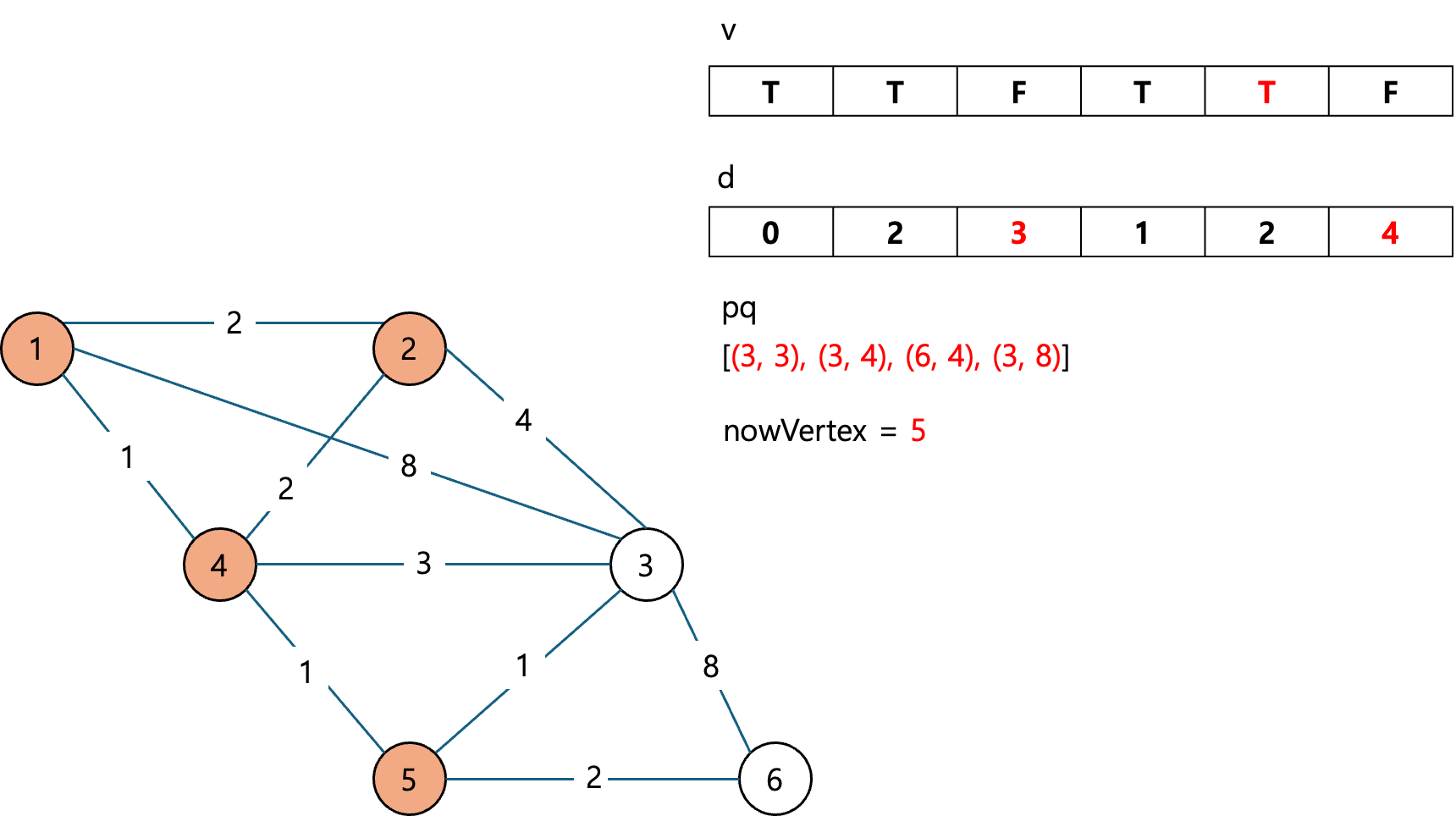
그리고 큐에서 3번 노드를 꺼내고 nowVertex = 3으로 갱신한다.
3과 연결된 정점을 탐색하면서 최소 비용 배열을 갱신해준다.

연결된 모든 노드들은 갱신되지 않고 탐색이 종료 된다.
그 다음 큐에서 노드를 뽑는데 3이므로 다음 노드를 다시 뽑으면 6이 뽑힌다.
nowVertex = 6으로 갱신

6의 경우 탐색도 현재 갱신되어 있는 배열들이 가장 저렴한 비용이므로 갱신되지 않고 종료된다.
그 다음 큐에서 3이 뽑히고 3은 이미 방문 배열이므로 탐색을 하지 않고 큐가 비어있어 종료된다.
최종적으로 1에서 다음 특정 노드들로 갈 수 있는 가장 최소 비용은 다음과 같게 된다.

이 과정을 수행하는 전체 실습 코드
package algorithmstudy.최단거리알고리즘.dijkstra;
import java.io.*;
import java.util.*;
public class Dijkstra {
static ArrayList<ArrayList<Node>> graph = new ArrayList<>();
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken()); // 정점의 개수
M = Integer.parseInt(st.nextToken()); // 간선의 개수
int start = Integer.parseInt(st.nextToken()); // 시작 정점
for (int i = 0; i <= N; i++) {
graph.add(new ArrayList<>()); // 그래프 초기화
}
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
int cost = Integer.parseInt(st.nextToken());
graph.get(from).add(new Node(to, cost));
graph.get(to).add(new Node(from, cost));
}
dijkstra(start);
}
static void dijkstra(int start) {
boolean[] v = new boolean[N + 1]; // 방문 체크 배열
int[] dist = new int[N + 1]; // 거리를 체크할 배열
int INF = 100000001; // 무한대의 비용 설정
Arrays.fill(dist, INF);
dist[start] = 0;
PriorityQueue<Node> pq = new PriorityQueue<>((n1, n2) -> n1.cost - n2.cost);
pq.add(new Node(start, 0));
while (!pq.isEmpty()) {
int nowVertex = pq.poll().index; // 우선순위 큐에서 뽑은 정점
if (v[nowVertex]) { // 정점이 이미 방문한 노드라면 거리 체크 안함
continue;
}
v[nowVertex] = true;
for (Node next : graph.get(nowVertex)) {
if (dist[next.index] > dist[nowVertex] + next.cost) {
dist[next.index] = dist[nowVertex] + next.cost;
pq.add(new Node(next.index, dist[next.index]));
}
}
}
// 큐가 비어서 더 이상 탐색할 곳이 없으면 지금까지 계산한 최소 거리 출력
for (int i = 1; i <= N; i++) {
System.out.println(dist[i] + " ");
}
}
}
class Node {
int index; // 정점을 저장
int cost; // 정점에 대한 비용을 저장
Node(int index, int cost) {
this.index = index;
this.cost = cost;
}
}
과정 하나씩 정리하는 것이 좀 힘들긴 했지만 나름대로 많이 정리가 될 수 있었다.
좋은 공부였다.