
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 너비 우선 탐색
- 구현
- Vue
- Spring Security
- 깊이 우선 탐색
- 소수 판정
- 알고리즘
- 정수론
- dfs
- 그래프 이론
- DB
- 프로젝트
- 정보처리기사
- 다이나믹 프로그래밍
- 프로그래머스
- 배포
- 재귀
- 그래프 탐색
- 문자열
- SWEA
- MYSQL
- 백트래킹
- n과 m
- 자료 구조
- springboot
- 수학
- JPA
- 백준
- 브루트포스 알고리즘
- 스택
- Today
- Total
영원히 남는 기록, 재밌게 쓰자
queryDSL을 사용해서 페이징 처리 해보기 본문
피드백 조회를 할 때 한 학생에 대한 피드백을 띄워줄 때 모든 피드백을 다 가져와서 페이지에 뿌려주고 있다.
만약 데이터가 많이 쌓인다면 문제가 발생할 수 있고 하나의 피드백을 찾기 위해 스크롤을 많이 내려야 할 수 있다.
이를 queryDSL의 페이징을 사용하여 페이징 처리를 시도하려고 한다.
queryDSL에서는 페이징 처리를 할 때에 PageImpl을 사용한다.
PageImpl 사용 방식
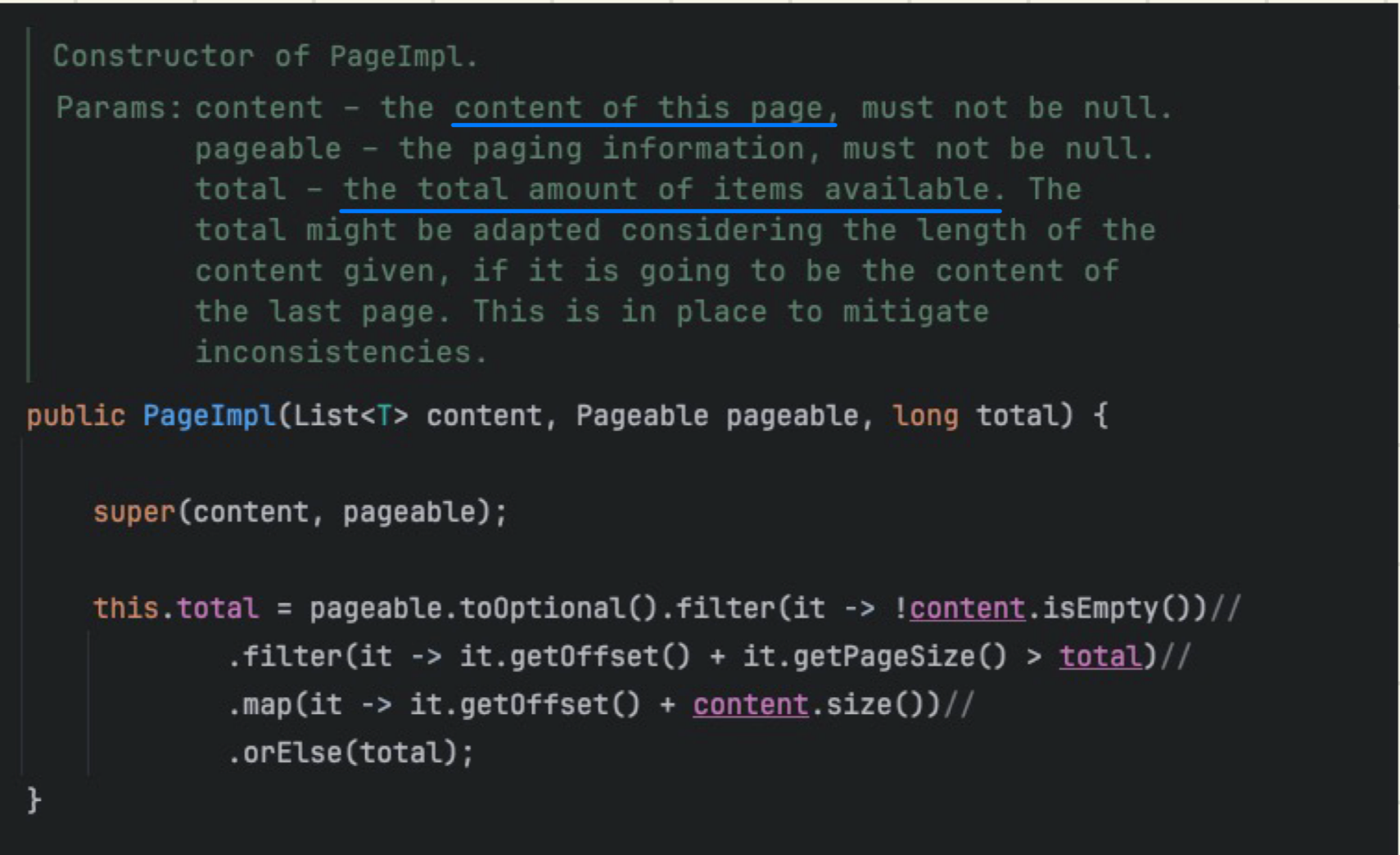
설명을 조금 보았는데
content: 페이징을 적용한 결과가 담기는 부분
total: 전체 페이징 적용이 가능한 총 크기
content의 인자는 JPAQuery (queryDSL)의 fetch() 결과를 의미한다.
피드백을 조회하기 위한 fetch() 구문
List<RecordRespDto> fetch = query.select(
new QRecordRespDto(record.id,
record.content,
record.teacher.name,
record.student.name,
record.status,
record.createDate,
record.modifiedDate)
)
.from(record)
.where(record.status.eq(RecordStatus.PUBLISHED)
.and(record.student.eq(student)))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
페이징을 처리할 메서드의 Pageable 객체로 부터 pageable.getOffset() 값과 pageable.getPageSize() 값을
offset()과 limit()에 적용해줄 것이다.
offset()과 limit()
offset() 메소드는 반환될 결과의 시작점을 지정
limit() 메소드는 반환될 결과의 최대 개수를 지정
fetch() 와 fetchOne()
fetch()
목적: 여러 개의 결과를 조회할 때 사용.
반환 형태: 조회된 결과를 List 형태로 반환한다. 결과가 없는 경우 빈 리스트를 반환.
fetchOne()
목적: 단 하나의 결과만 조회할 때 사용. 주로 유니크한 조건으로 데이터를 조회할 때 사용.
반환 형태: 단일 객체를 반환한다. 결과가 없는 경우 null을 반환. 결과 값이 둘 이상이면 NonUniqueResultException 예외 발생.
new PageImpl()은 총 두 번의 쿼리를 실행하여 페이징을 적용한다는 것을 알 수 있었습니다.
@QueryProjection
이 어노테이션을 dto의 생성자에 적용하면 queryDSL에서 select 결과를 dto형태로 받을 수 있다.
select 절에 받아올 결과들 중 dto를 매핑하기 위한 데이터들만 뽑아서 넣어주면 된다.
PageableExecutionUtils를 사용하여 PageImpl() 방식의 count 쿼리 개선하는 방법
PageableExecutionUtils를 사용하면 count 쿼리를 날리는 방식 보다 비용이 저렴하다고 한다.
다른 블로그를 참고 했을 때 첫 페이지와 마지막 페이지에서는 count 쿼리가 생성되지 않기 때문에 그런 것 같다.
(설명이 좋아서 공부할 겸 해당 블로그의 설명을 필사하였다.)

PageableExecutionUtils 역시 반환은 PageImpl 객체를 반환하는 것을 알 수 있었다.
PageImpl() 객체에서는 세번째 인자의 total 변수를 무조건 필수로 호출해야 하지만 PageableExecutionUtils 의 getPage에서는 totalSupplier라는 함수형 인터페이스를 통해 count 쿼리의 생성을 한번 막아주게 되어 비용이 조금 더 저렴하다고 하는 것 같다.
결과 테스트 해보기
@Test
public void createDummyRecordData(Student student, Teacher teacher) {
for (int i = 0; i < 300; i++) {
Record record = Record.builder()
.student(student)
.teacher(teacher)
.content((i + 1) + "번 테스트 피드백 입니다.")
.status(RecordStatus.PUBLISHED)
.build();
record.addStudent(student);
record.addTeacher(teacher);
recordRepository.save(record);
}
}
@Test
void 페이징_처리_피드백_조회_테스트() {
//given
Student s = Student.builder()
.name("철수")
.userId("cs@time.com").password("1234")
.phoneNumber("010-1111-2222").schoolName("용호초등학교")
.classType(ClassType.ELEMENTARY).grade(1)
.memberType(MemberType.STUDENT).gender(GenderType.MALE)
.address(new Address("반림동", "현대 아파트", "102-1201"))
.attendanceStatus(AttendanceStatus.Y)
.build();
Teacher t = new Teacher("줄리아", "1234", "010-1212-3456", MemberType.TEACHER, Position.TEACHER, "julia@time.com", GenderType.FEMALE);
Student student = studentRepository.save(s);
Teacher teacher = teacherRepository.save(t);
createDummyRecordData(student, teacher);
//when
Pageable pageable = PageRequest.of(3, 10);
Page<RecordRespDto> result = recordRepository.findAllPaging(student, pageable);
//then
log.info("result={}", result);
assertThat(result.getSize()).isEqualTo(30); // 300개를 10개씩 페이징 처리해서 30개가 나와야 함
}
content = 10개, 요청 페이지 = 20 일 때 처음 페이지를 로딩하는 경우

페이징하고자 하는 사이즈가 더 커서 content의 size가 세번째 인자에 들어간다. 그리고 fetchOne()이 호출 되지 않으므로 count쿼리가 날아가지 않음
content = 10개, 요청 페이지 = 8 일 때 처음 페이지를 로딩하는 경우


이 경우는 세번째 인자로 count::fetchOne 이 호출 되면서 count 쿼리가 생성 되는 것을 확인할 수 있었다.
마지막 페이지 오프셋을 요청했을 때의 결과는 페이지 사이즈는 8개지만 가져온 결과는 2개를 가져오는 것을 확인할 수 있었다.

이 부분에서 알 수 있었던 것은 첫 페이지에 머무는 페이지가 많은 곳에는 이런 성능 최적화가 많이 이루어질 수 있다는 것을 알 수 있었다.
이 경우라면 내가 진행중인 서비스에 사용하면 좋겠다는 생각이 들었다.
페이징과 동작 원리를 잘 이해하지 못했는데 참고한 블로그를 통해 공부를 많이할 수 있었다.
'springboot > JPA' 카테고리의 다른 글
| 엔티티 매핑에 대해서 (0) | 2024.06.11 |
|---|---|
| API 개발 공부 - 지연 로딩과 조회 성능 최적화에 대해서 (0) | 2024.05.26 |
| 프록시 (0) | 2024.02.27 |
| 다대일(N:1) 연관 관계에서 양방향 단방향 매핑과 연관 관계의 주인에 대해서 알아보자. (2) | 2024.02.24 |
| 영속성 컨텍스트의 플러시(flush)에 대해서 (0) | 2024.02.21 |


